Auteurs :
Jérôme Dupré, avocat au barreau de Nantes, docteur en droit
Jacques Lévy Véhel, président de Case Law Analytics, directeur de recherches chez Inria, docteur en mathématiques.
Introduction
L’utilisation d’outils mathématiques et informatiques avancés en droit est une réalité depuis quelques années. Ceux-ci sont utilisés quotidiennement pour la préparation de contrats, leur analyse en vue de « due diligences », la recherche documentaire et lors de procédures alternatives de règlement des différends, pour ne citer que quelques domaines.
Dans cet article, nous nous concentrons sur une technologie particulière et un domaine d’application bien précis, afin d’entrer dans quelques détails et d’éclairer le lecteur sur les possibilités, les limites et les enjeux associés à l’usage de tels outils : nous nous intéresserons à l’utilisation de l’intelligence artificielle pour la quantification de l’aléa judiciaire.
Il y a plusieurs façons d’envisager l’irruption de cette technologie en droit : considérons d’abord le point de vue des juristes. Pour l’institution judiciaire et pour les magistrats, la gestion de l’engorgement des tribunaux est certainement un enjeu majeur qui mérite que l’on trouve des solutions permettant de favoriser les modes alternatifs de règlement des différends, y compris, si besoin, en recourant à des outils numériques. Pour les professionnels du droit, comme les avocats ou les directeurs juridiques, savoir anticiper le risque et le provisionner correctement est bien sûr crucial.
Si maintenant nous nous plaçons du côté des scientifiques, quantifier un aléa irréductible comme l’est l’issue d’un contentieux, est un champ d’application passionnant pour les théories développées récemment, qui font appel à des domaines comme les probabilités, les statistiques ou l’apprentissage automatique. Adapter les dernières avancées survenues dans ces disciplines et les mettre à l’épreuve d’un champ totalement nouveau comme le droit ne peut qu’être enrichissant à tout point de vue.
Nous espérons que les explications que nous présentons ci-dessous, de la démarche scientifique employée pour quantifier l’aléa judiciaire, permettront aussi d’en finir avec les fantasmes autour de ladite « justice prédictive » qui sont préjudiciables à une analyse sereine par les juristes des apports actuels et futurs de l’intelligence artificielle au droit. Une compréhension minimale est en effet un préalable, afin que le dialogue nécessaire avec la communauté des mathématiciens s’engage sur des bases propres à assurer que l’irruption de ces nouveaux outils se traduise le plus rapidement possible par un meilleur fonctionnement de notre système judiciaire et non par une dégradation de celui-ci.
Pourquoi parler de « justice prédictive » n’a pas de sens et s’avère dangereux
« Prédire la justice » signifie dans notre contexte que l’on pourrait, grâce à un algorithme, « deviner » la décision qui sera prise par un juge sur un dossier donné. Il est important de comprendre que le concept de justice prédictive est non seulement vide de sens, mais, de plus, dangereux.
Vide de sens, car il n’y a rien à prédire. En effet, comme démontré par exemple dans une étude parue dans les Cahiers de la Justice (voir Des juges sous influence, Cahiers de la Justice, 2015/4), non seulement deux juges différents peuvent rendre des décisions différentes sur un même dossier, mais aussi un seul et même juge peut adopter des solutions divergentes dans des affaires présentant les mêmes caractéristiques. La longueur de l'audience, la nature du dossier traité juste avant et d’autres paramètres peuvent avoir une incidence forte sur la solution donnée. Plus profondément, même si deux affaires sont en apparence similaires, des différences subtiles et non quantifiables font que rendre des décisions différentes est parfaitement compréhensible : c’est toute la difficulté et l’art de rendre la justice que de tenter de traiter tout le monde de manière égale, tout en tenant compte des particularités intrinsèques de chaque situation. Le projet même de prédire la justice est donc fondamentalement erroné.
Il est, de plus, dangereux, car trompeur : en effet, si l’on imagine qu’un jour un ordinateur pourra prédire une décision, un instant de réflexion suffit à comprendre qu’en réalité il prescrira cette décision : c’est la machine qui dira le droit. La société n’est pas prête à déléguer ce genre de pouvoir à un ordinateur, et c’est tant mieux. Tous les acteurs, juristes, mathématiciens, simples citoyens, doivent se mobiliser contre un tel projet. En effet, nous sommes prêts à accepter la sentence d’un juge, car celui-ci est à la fois un expert et un humain impartial : il peut appréhender les faits et les organiser selon les règles de droits adéquates, mais est aussi capable d’entrer en empathie avec le ressenti de chacune des deux parties au moment de prendre sa décision, en recherchant au-delà de la règle de droit une solution équitable, ce qu’une machine ne peut pas faire à ce jour.
La seule approche raisonnable est de quantifier de façon probabiliste l’aléa judiciaire
Modéliser le raisonnement juridique ne paraît pas atteignable pour le moment ; même si c’était le cas, une approche déterministe (dont il serait naïf de croire qu’elle repose réellement sur un syllogisme, lequel est surtout utilisé à des fins de justification juridique de la décision) ne serait pas souhaitable, car elle ne pourrait pas prendre en compte les variations non quantifiables entre des dossiers très proches, qui se traduisent par ce qui apparaît comme une incertitude irréductible sur l’issue d’un procès. Les situations comportant un aléa inhérent sont communes dans divers domaines, comme la météorologie, la médecine ou la finance. Une démarche scientifique que l’on met couramment en œuvre pour traiter ce type de cas s’appelle modélisation probabiliste. Voici comment elle se concrétise pour la problématique qui nous concerne.
L’idée de base est de repenser la jurisprudence comme une donnée à traiter, en quelque sorte, sous un angle « non juridique » : il s’agit de travailler à dégager du « patrimoine jurisprudentiel » des éléments propres à étendre le bénéfice du jugement, de manière à favoriser des anticipations. En effet, dès lors qu’un jugement comporte nécessairement une part d’aléa, en particulier à cause de conflits de normes et de valeurs, la maîtrise de cet aléa favorise la possibilité d’éviter le recours systématique au jugement, ce qui constitue une alternative plus douce que la déjudiciarisation, puisqu’elle ne prive pas les parties d’un droit d’accès à la justice.
Techniquement, ceci nécessite d’associer des nombres à des situations de droit ou de fait, soit directement (données chiffrées dans la décision), soit indirectement. Pour cela, il faut commencer par choisir un contentieux bien circonscrit, par exemple la rupture brutale des relations commerciales établies, le versement d’une prestation compensatoire ou encore d’une indemnité pour licenciement sans cause réelle et sérieuse. S’ensuit une phase d’expertise juridique, pendant laquelle il s’agit de déterminer, avec l’aide de spécialistes du domaine, les principaux critères de droit, mais aussi de fait, sur lesquels s’appuie, de manière consciente ou non, un juge pour prendre sa décision dans ce type de dossier : pour une prestation compensatoire, on prendra en compte, par exemple, la durée du mariage, les revenus des époux, leur patrimoine, etc.
On cherche ensuite à rendre compte de la façon dont les juges parviennent à leurs conclusions. Pour ce faire, des modèles mathématiques sont créés en enseignant à la machine à prendre des décisions similaires à celles de juges humains. C’est à ce stade que l’on s’appuie sur l’analyse d’une quantité significative de jurisprudence à la lumière des critères précédemment définis. Diverses techniques sont utilisées, en particulier empruntant au sous-domaine de l’intelligence artificielle appelé apprentissage automatique.
Pour tenir compte de l’aléa mentionné aux paragraphes précédents, il est nécessaire de reproduire non pas une seule réponse, mais un éventail de « jugements » possibles : les modèles mathématiques sont alors mis au point avec la consigne que l’ensemble de ces jugements virtuels coïncide, de façon prouvée et globalement, avec ceux qui seraient rendus sur un dossier donné devant une juridiction donnée: autrement dit, la modélisation a pour vertu de garantir que, par exemple, les décisions rendues par la cour d’appel de Paris sur un échantillon de cent dossiers caractérisés par des critères prescrits sont exactement les cent résultats calculés par la machine quand on l’interroge avec ces critères.
Il est important de comprendre qu’il n’est pas possible de faire mieux : à cause du fait qu’aucun jeu de critères ne peut complètement décrire une situation, et que deux juges différents peuvent prendre des décisions différentes, le seul objectif scientifiquement fondé est de rendre compte de la diversité des décisions qui seraient prises compte tenu de l’information incomplète dont on dispose : l’aléa résiduel reflète à la fois la variabilité inhérente au jugement humain et le fait qu’aucun ensemble de critères, si riche soit-il, ne peut épuiser l’infinie diversité des cas individuels.
Comme on le voit, la démarche fait intervenir autant, sinon plus, l’expertise juridique humaine que la modélisation et l’intelligence artificielle. Mais surtout, elle ne peut aboutir qu’à travers une collaboration étroite et un dialogue suivi entre juristes et mathématiciens.
Notons que la procédure décrite ci-dessus est fort différente de la simple utilisation de statistiques : dans ce dernier cas, on se contenterait de calculer que, sur l’ensemble des décisions dans des dossiers présentant telles et telles caractéristiques, un certain pourcentage a tranché en faveur de l’une ou l’autre des parties, et a le cas échéant accordé tel montant moyen.
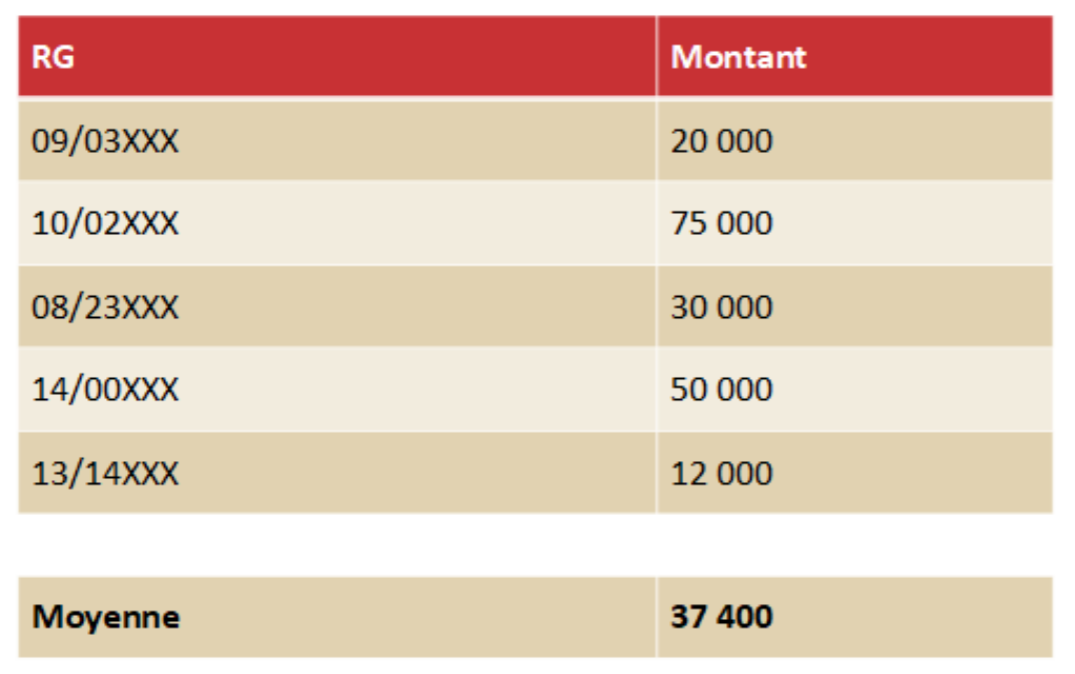
Un premier problème avec cette approche est que, dès que le nombre de critères est élevé, le panel de décisions sur lequel on effectue les calculs est de petite taille : pour dix critères et un contentieux typique, on ne trouvera, en général, que quelques dossiers pertinents. Les pourcentages et moyennes estimés seront alors, compte tenu de la taille très insuffisante de l’échantillon utilisé dans un tel cas, peu fiables et donc susceptibles de donner des résultats aberrants. Pour éviter cet écueil, on peut imaginer réduire le nombre de critères considérés, mais alors la variabilité des décisions devient très importante. Le tableau ci-dessous présente 5 décisions à la cour d’appel de Paris concernant une prestation compensatoire pour un couple marié depuis 14 ans, le créancier ayant 44 ans et ayant des revenus d’environ 20 000 euros, le débiteur ayant 46 ans et ayant des revenus d’environ 50 000 euros, soit 6 critères. Comme on le voit, les montants prononcés vont de 12 000 à 75 000 euros, et la valeur moyenne de 37 400 euros n’est que très peu informative.
La seconde difficulté est que, par définition, les statistiques ne donnent que des informations sur le passé. Ainsi, une telle approche, transposée, par exemple, au domaine de la météorologie, reviendrait à dire, que, pour quantifier le risque de précipitation un certain jour, on ferait des moyennes sur des jours « similaires » dans le passé. Les météorologues ne procèdent évidemment pas de cette manière : ils ont identifié les variables clés qui gouvernent l’évolution du temps (l’équivalent des critères dans notre cas) et ont modélisé leurs interactions au sein d’un modèle afin de calculer leurs prévisions. C’est exactement la démarche, seule pertinente d’un point de vue scientifique, que nous avons décrite au paragraphe précédent.
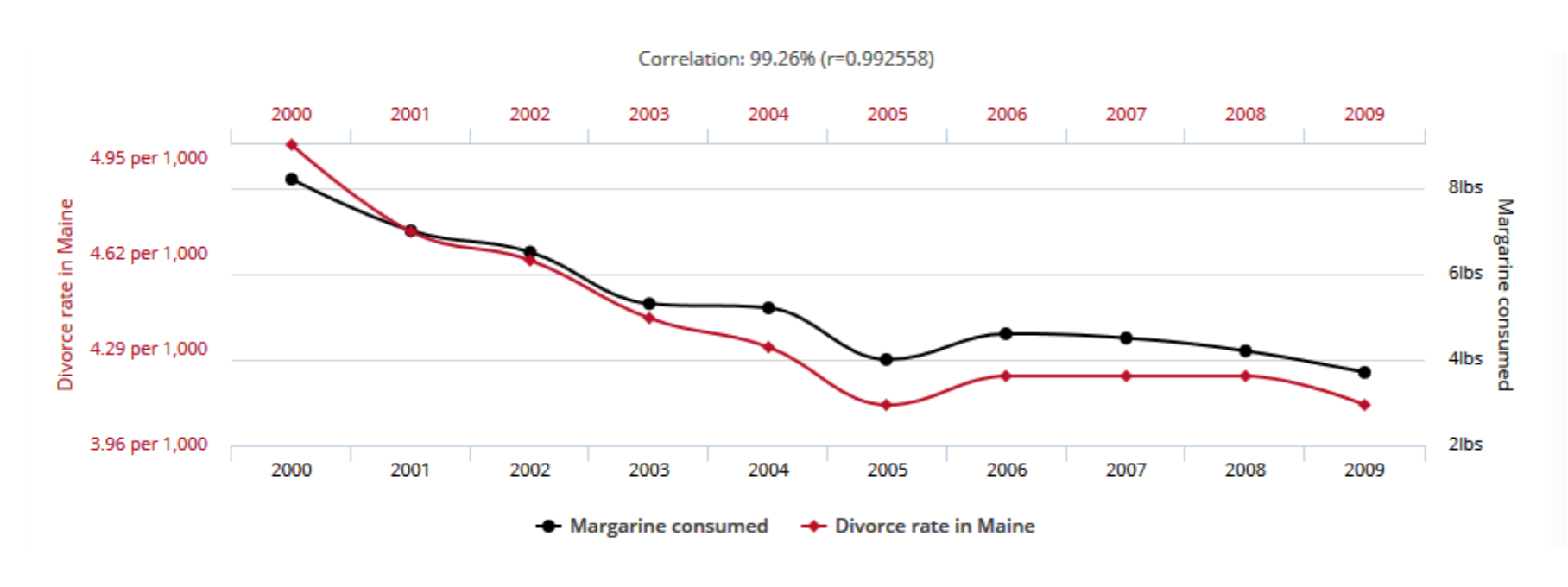
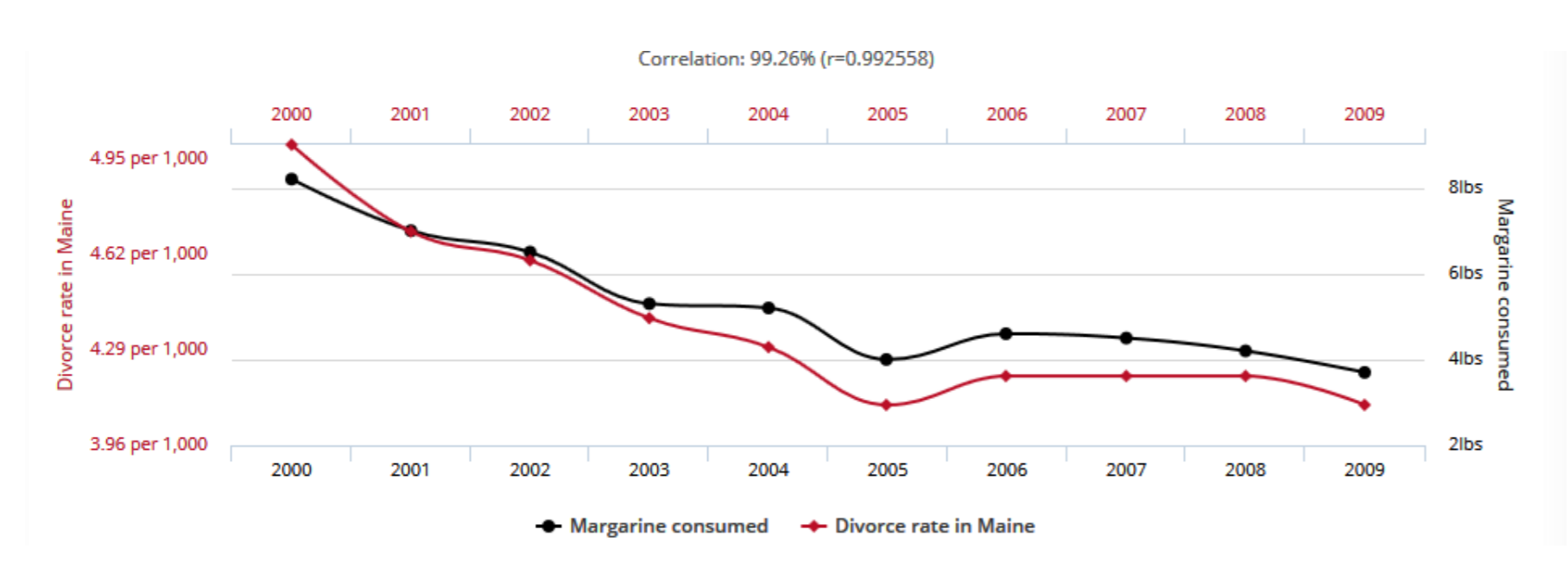
Enfin, un troisième problème avec une approche purement statistique est qu’elle peut mettre à jour et s’appuyer sur des corrélations qui n’ont aucune pertinence. Comme on le sait, corrélation n’est pas causalité, et deux facteurs corrélés peuvent l’être sans entretenir la moindre relation, soit parce qu’ils sont tous deux les conséquences d’un facteur commun, soit tout simplement par le fait du hasard : ceci est illustré par la figure ci-dessous (1) , sur laquelle on observe une corrélation presque parfaite entre taux de divorce dans l’état américain du Maine et consommation de margarine par habitant dans le monde, entre 2000 et 2009.
L’aspect performatif
Par performativité, nous entendons ici le phénomène selon lequel l’utilisation d’un modèle mathématique ou plus généralement d’un outil descriptif dans un champ donné peut parfois dépasser la simple description pour modifier ce champ. Ceci est une spécificité des sciences humaines et sociales : un tel effet n’apparaît pas dans les sciences naturelles. Comme l’écrit A.S. Blinder dans How the Economy Came to Resemble the Model (Business Economics, 35- 1, 2000), « les microbes n'ont pas modifié leur comportement pour tenir compte de la théorie de Pasteur, et l'orbite de Mercure n'a pas non plus été perturbée pour faire en sorte que celle d'Einstein ne le soit pas ». Si la situation est très différente en sciences sociales, c’est bien sûr parce que la réalité décrite par les outils est construite par des humains : ces mêmes humains, lorsqu'ils appliquent les outils, modifient généralement cette réalité, dès que ceux-ci ne sont pas entièrement adéquats (ce qu’ils ne sont jamais). Les exemples abondent en finance et en économie, où ils ont été largement documentés et étudiés tant par des économistes que par des sociologues. Pour citer encore Blinder : « on aurait pu supposer que les économistes devraient adapter leurs modèles à la réalité plutôt que l'inverse. C'est certainement ainsi que cela fonctionne en sciences naturelles. Mais les économistes semblent avoir plié la réalité (au moins quelque peu) à leurs modèles ».
Bien évidemment, le droit ne va pas échapper à ce type d'effets. Commençons par discuter brièvement de ce qui pourrait se passer en cas d’utilisation d’outils statistiques sans véritable fondement scientifique (en particulier n’exploitant pas de modèles mathématiques). Les conséquences performatives, potentiellement très dommageables, peuvent être réparties en deux catégories :
- performativité convergente : l’utilisation de simples statistiques sur le passé, présentant en sus uniquement des moyennes non qualifiées (c’est-à-dire sans leur marge d’erreur), si elle venait à influencer les juges, conduirait non seulement à une uniformisation des pratiques, mais, ce qui est nettement plus grave, à laisser à terme la machine décider à la place de l’homme : comme dit ci-dessus, la justice prédictive serait alors en réalité une justice prescriptive. Nous pensons que ce danger est actuellement surévalué dans les discussions sur la justice prédictive. Nous faisons en effet confiance à l’indépendance des magistrats pour limiter cet effet ;
- performativité divergente : malheureusement, l’effet inverse, qui nous semble avoir une plus grande probabilité de se réaliser, est encore plus dommageable. Sans trop entrer dans les détails, qui font l’objet d’une étude en cours dans le cadre d’un projet financé par la mission de recherche Droit et Justice, nous craignons d’assister à l’enchaînement suivant :
o les outils de « justice prédictive » vont permettre à certains professionnels de se satisfaire de solutions de facilité, qui donnent une fausse idée du résultat « probable » (en réalité moyen) de l’issue d’un contentieux ;
o ceci peut conduire une partie des justiciables, les moins à même de se défendre, à renoncer à aller au tribunal et à se contenter de transiger sur des bases fausses,
o alors que d’autres, plus informés et mieux armés, soit utiliseront de meilleurs outils soit iront au tribunal ;
o or, les magistrats, dont nous pensons fermement qu’ils continueront à remplir leur tâche avec les compétences techniques et humaines requises, rendront souvent des décisions différentes ou très différentes de ces « prédictions » ;
o à moyen terme, cette justice à deux vitesses diminuera la confiance que le justiciable place dans l’institution, fragilisant ainsi notre système judiciaire.
Bien sûr, même des outils mathématiquement fondés auront probablement aussi des effets performatifs. Mais comme ils explicitent leurs modèles, ces effets peuvent être eux-mêmes modélisés et pris en compte pour les contrôler et si possible les orienter vers des directions « vertueuses ». En ce qui concerne la méthodologie expliquée dans cet article, on peut proposer l’analyse suivante. Comme on va le voir et comme c’est souvent le cas, la performativité n’arrive pas là où on l’attend. Dans les contentieux que l’on peut traiter par ces approches, il y a toujours des aspects quantitatifs et qualitatifs. La technologie exposée ici laisse de côté les aspects qualitatifs, et ce, de façon « active » : le fait qu’il y ait des aspects qualitatifs non pris en compte est présenté de manière visuellement évidente à l’utilisateur via l’éventail des jugements virtuels : la distribution des décisions possibles reflète le fait que les données quantitatives n’épuisent pas un dossier. Tout ce qui n’est pas appréhendé par ces données laisse place à interprétation et se traduit par un éventail de décisions, précisément celui qui est présenté. La technologie demande, en revanche, que les informations chiffrées soient fiables. Or, en pratique, il arrive souvent que, sur des données factuelles (salaire, patrimoine, durée d’une relation commerciale) règne un flou parfois volontairement entretenu : que les deux parties ne soient pas d’accord, par exemple, sur l’évaluation d’un patrimoine dans un dossier de prestation compensatoire est compréhensible. Que cette indétermination ne soit pas levée à un moment ou à un autre semble préjudiciable à un bon fonctionnement du système, et c’est pourtant ce que l’on observe parfois. L’effet performatif d’un outil mathématique pourrait alors être de contraindre tous les acteurs à se mettre d’accord sur les aspects quantitatifs, laissant les marges d’appréciation pour les aspects qualitatifs, ce qui semble représenter un progrès.
Quel encadrement juridique ?
À ce jour, le droit n’est pas muet en ce qui concerne les algorithmes mis en œuvre… par l’administration ou liés au profilage d’un individu.
Le décret n° 2017-330 du 14 mars 2017 précise ainsi les modalités de la demande et de la communication des règles définissant un traitement algorithmique lorsque celui-ci a participé au fondement d'une décision individuelle. Selon les termes de ce décret, l'administration communique notamment à la personne faisant l'objet d'une décision individuelle prise sur le fondement d'un traitement algorithmique, à la demande de celle-ci, « sous une forme intelligible et sous réserve de ne pas porter atteinte à des secrets protégés par la loi, les informations suivantes :
1° le degré et le mode de contribution du traitement algorithmique à la prise de décision ; 2° les données traitées et leurs sources ; 3° les paramètres de traitement et, le cas échéant, leur pondération, appliqués à la situation de l'intéressé ; ; 4° les opérations effectuées par le traitement ; ». (article R. 311-3-1-2 du code des relations entre le public et l'administration). »
Il faut également compter avec la Commission d’accès aux documents administratifs (CADA), créée par la loi n° 78-753 du 17 juillet 1978, qui a notamment considéré « que le code source d’un logiciel, qui est un ensemble de fichiers informatiques contenant des instructions devant être exécutées par un micro-processeur, revêt le caractère de documents administratifs communicables à toute personne qui en fait la demande, conformément aux articles L 300-2 et L 311-1 du code des relations entre le public et l’administration » (2 ).
Par ailleurs, l’article 10 de la loi 78-17 du 6 janvier 1978 modifiée, dite « informatique et libertés » dispose : « Aucune décision de justice impliquant une appréciation sur le comportement d’une personne ne peut avoir pour fondement un traitement automatisé de données à caractère personnel destiné à évaluer certains aspects de sa personnalité.
Aucune autre décision produisant des effets juridiques à l’égard d’une personne ne peut être prise sur le seul fondement d’un traitement automatisé de données destiné à définir le profil de l’intéressé ou à évaluer certains aspects de sa personnalité (…). »
Enfin, sous réserve de certaines exceptions, l’article 22 du règlement général sur la protection des données (RGPD) prévoit que « [l]a personne concernée a le droit de ne pas faire l'objet d'une décision fondée exclusivement sur un traitement automatisé, y compris le profilage, produisant des effets juridiques la concernant ou l'affectant de manière significative de façon similaire. »
Dans la démarche que nous proposons, les algorithmes ne sont pas mis en œuvre par l'administration et surtout ne doivent en aucun cas fonder une décision exclusivement sur un traitement automatisé. Est-ce à dire qu’ils ne doivent pas faire l’objet d’évaluations ? Nous ne le pensons pas.
Comment s’assurer de la pertinence des résultats ?
Transparence, loyauté, neutralité sont des qualités que l’on doit exiger de tout système de quantification des risques judiciaires, sous peine de graves dérives. Plusieurs solutions peuvent être mises en place dans ce but.
Si de tels outils sont développés et commercialisés par des entreprises, il peut sembler difficile de demander d’ouvrir le code implémentant les algorithmes, qui représente en général un fort investissement. On peut, en revanche, tout à fait envisager, comme cela se pratique dans d’autres domaines où un secret industriel doit être protégé tout en garantissant le bon fonctionnement d’un système, de faire intervenir une autorité de certification tenue à la confidentialité.
Ce type de procédure est certainement rassurant, mais il ne répond que très partiellement à la question de la pertinence. Il est en effet très difficile, voire dans certains cas probablement presqu’impossible, de vérifier qu’un code complexe est neutre et loyal, en particulier parce que ces qualités dépendent d’un enchevêtrement d’interactions permanentes, avec un ensemble mouvant et difficilement maîtrisable de données comme l’est la jurisprudence. La méthodologie de sélection, la qualité et l’organisation des sources sont également des aspects très déterminants.
Une alternative est d’utiliser des approches plus pragmatiques, plus simples et finalement plus à même de répondre aux exigences parfaitement légitimes de vérification. Puisqu’après tout on demande à ces systèmes de refléter de façon fidèle les pratiques des juges, le test ultime consiste à confronter en permanence, sur des échantillons pris au hasard, les décisions prises par la machine à celles d’un panel suffisamment large de magistrats, et de vérifier qu’elles sont globalement indistinguables. Bien sûr, puisqu’on ne peut effectuer une telle vérification à chaque fois que le système mathématique est utilisé, il se pourrait qu’apparaissent parfois des divergences non détectées. C’est pourquoi il est essentiel de maintenir un accès garanti à un juge, en toutes circonstances, pour tout justiciable qui mettrait en question les résultats d’une évaluation automatique. C’est le sens des articles mentionnés au paragraphe précédent. De telles situations permettront d’ailleurs d’effectuer des contrôles additionnels dans des cas potentiellement « à risque ».
Une autre solution, qui permet de comprendre le fonctionnement de ces systèmes mieux que l’examen d’un code informatique, est de procéder à des analyses contrefactuelles. Sans trop rentrer dans des détails qui dépassent le cadre de cet article, une possibilité est de demander à la machine, en partant d’un dossier donné et des décisions calculées, de présenter l’ensemble des modifications minimales des critères du dossier qui conduiraient à un éventail prescrit de résultats différents. Par exemple, si pour une affaire concernant une rupture brutale de relations commerciales établies, le modèle calcule qu’il y aura 30% des décisions qui accordent une indemnité, et parmi celles-ci, 20% donnant 7 mois de préavis et 80 % donnant 8 mois, on peut demander à la machine d’indiquer de combien, par exemple, il faudrait changer la durée de la relation, et, concomitamment, le fait que les contrats soient exclusifs ou tacitement reconduits, pour que les résultats deviennent 40% de décisions accordant une indemnité, avec 6 mois dans 30% des cas et 7 mois dans 70% des cas. Bien que plus complexe à appréhender pour l’usager (mais simple à calculer pour la machine), cette approche a le mérite de mesurer la sensibilité des modèles et de mettre en lumière, de manière plus « organique », leur fonctionnement.
Quoi qu’il en soit, pour porter un jugement sur la qualité d’une technologie, il sera nécessaire de recourir à l’expertise conjointe de scientifiques reconnus dans le domaine de l’intelligence artificielle et de juristes compétents dans le champ pour lequel on souhaite quantifier l’aléa.
Des questions éthiques multiples
Au-delà de cette évaluation scientifique, la conception d’une telle technologie amène une réflexion en amont sur les domaines du droit susceptibles d’être traités. Doit-on aborder le champ pénal ? Il n’est pas certain qu’une trop grande prévisibilité soit toujours souhaitable.
Faut-il faire apparaître des biais qui existent dans la prise de décision des juges (comme le sexe, par exemple) ? Il semble préférable d’éviter d’orienter les parties dans le sens d’une telle discrimination, qui ne reflète évidemment pas la volonté du législateur ou du régulateur (même si en avoir conscience est utile pour aider à corriger ces biais).
D’autres questions se posent également. Par exemple, à qui fournir une telle technologie ? Doit-on la communiquer au grand public, aux professionnels ? Il est sans doute souhaitable d’élaborer une réflexion au cas par cas, en fonction de la complexité de l’outil et des enjeux concernés. Comment assurer l’égalité des armes entre les parties ? Le prix d’une telle technologie devrait être accessible.
Comment éviter absolument les risques de discrimination dans l’évaluation des risques judiciaires ? Il est nécessaire que chaque critère ait un lien direct et unique avec le sujet traité.
Peut-on accepter le profilage des magistrats ? C’est une réalité outre-Atlantique. Dans notre pays, la justice est rendue au nom du peuple français mais n’y-a-t-il pas un risque de pression si de telles informations sont accessibles à tous et non à la seule autorité judiciaire ?
Peut-on accepter de présenter des résultats sans leur degré de fiabilité ? Nous ne le pensons pas. Ne faut-il pas garder une certaine mesure dans l’interprétation des résultats ?
Il est en tout cas nécessaire d’interroger les professionnels concernés pour les amener à s’exprimer sur les résultats obtenus. La qualité scientifique d’une approche mathématique implique d’avoir, en droit et en sciences humaines, une bonne connaissance des règles, des contraintes, et plus largement, des réalités de terrain, pour élaborer des outils qui soient pertinents et utiles.
Perspectives
Les technologies décrites ci-dessus ouvrent de nombreuses possibilités, dont nous n’apercevons probablement qu’un petit échantillon à ce jour. Elles ont certainement l’avantage d’être en phase avec les exigences d’une société qui accepte de moins en moins le risque et qui réclame de plus en plus de prévisibilité. Un tel objectif peut être partiellement atteint tout en préservant la part irréductible de singularité et de dimension humaine, à condition de garder le juge au centre de tout dispositif. Ce dernier continuera à concilier règle générale et prise en compte des situations particulières, mais pourra alors se concentrer sur ses fonctions essentielles - à savoir trancher des conflits de normes, de valeurs et produire du symbolique - là où c’est nécessaire. Dans tous les autres cas, les modèles mathématiques pourront avantageusement guider les parties lors de procédures alternatives de règlement des différends.